Leacture: Deep Learning for everyone
Deep Learning
Perceptron
-
뉴런의 원리이용 : 입력 신호들이 들어왔을 때 임계값을 넘어서면 신호를 전달한다.
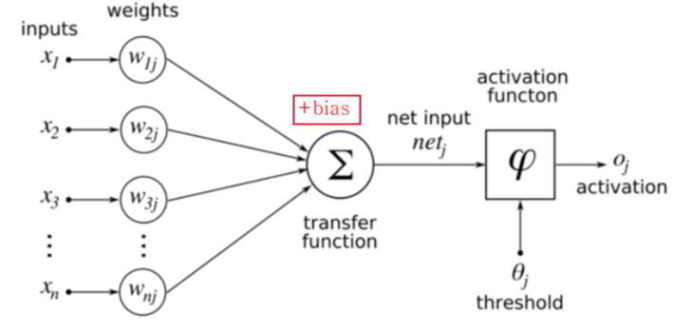
- AND, OR과 같은 문제에서 하나의 Line으로 이용가능
-
하지만 XOR(두 입력이 같으면 0, 다르면 1.의 경우에는 하나의 Linear line으로 구분 불가능하다.
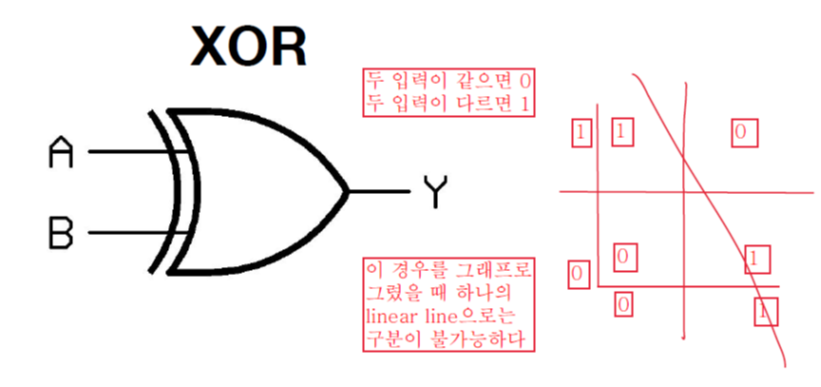
- 이후로 한동안 딥러닝 분야에서 발전이 없었다.
Multi Layer Perceptron
- 위의 XOR문제 해결을 위한 방법(선을 2개 이상 긋는다.)
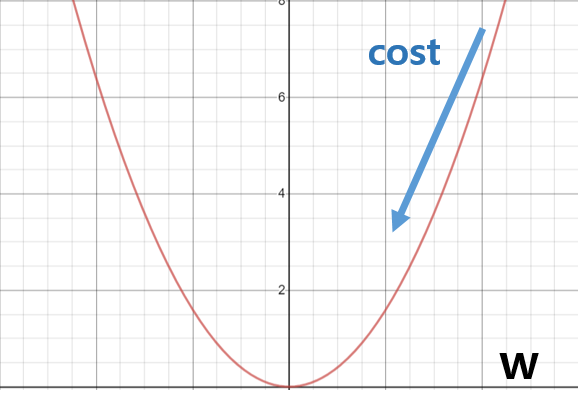
Backpropagation
- Loss를 없애는 방향으로 Weight를 업데이트해나간다.
- dE/dw를 계산한다 -> dE/dw의 반대 방향으로 w를 업데이트 해나간다. -> E가 줄어든다(Learning Rate를 활용한다)
- Chain Rule 이용: g는 활성함수 -> dE/dw = dE/dg * dg/dw
Binary Cross Entropy
- 이진분류에서 사용되는 Loss Function
- 추론값과 그에 대한 정답값들의 괴리(손실)을 합한 값
- Y -> 정답 / Y_pred -> 추론값
- L = -(Ylog(Y_pred) + (1 - Y_pred)) (Y와 (1-Y)는 0,1 둘 중 하나)
ReLU
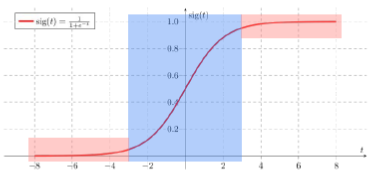
Sigmoid
- 양 끝부분에서 gradient를 구하면 너무 작은 값이 나온다.
- Loss로부터 전파되는 Gradient가 소멸되는 효과 (Vanishing Gradient)
ReLU
- f(x) = max(0, x)
- 음수의 경우에는 Gradient가 아예 소멸되는 문제점이 있다.
- 이외에 tanh, leaky_relu등이 있다.
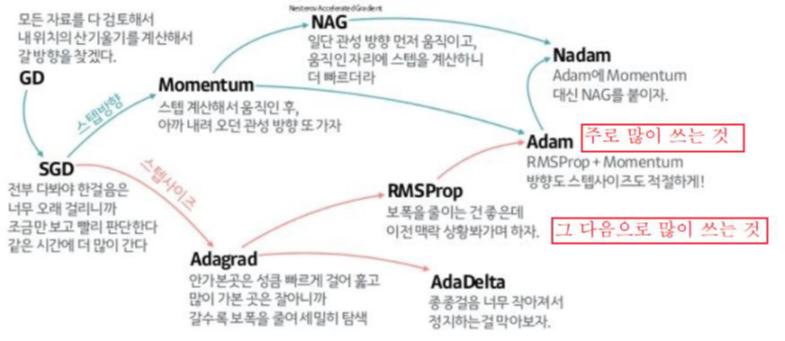
Optimizer
- 여러가지 optimizer가 있지만 adam을 많이 사용한다.
Weight Initialization
- initialization을 잘 한 모델이 에러 최솟값에 수렴을 잘한다.
- 가장 피해야할 초기화: 모든 값을 0으로 하는것.
Restricted Boltzmann Machine
- 이미 모델을 몇번 돌린 weight를 가지고 training을 한다.
Xavier / He initialization
- 최근에는 He initialization을 쓴다고 한다.

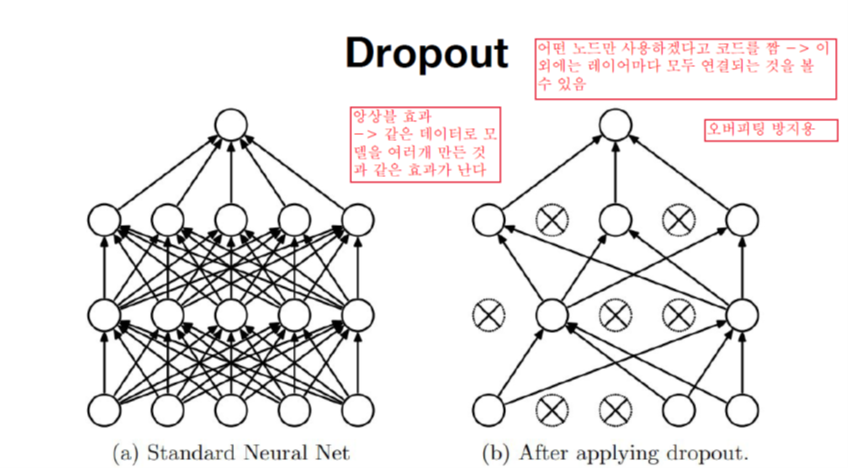
Dropout
- 너무 Train Set에만 잘 맞추어 훈련되는 Overfitting을 피하기 위한 방법이다.
- layer마다 일부 node만 이용한다. -> 사용하는 node끼리는 모두 연결
- 네트워크 앙상블 효과를 낼 수 있다.(같은 모델을 여러개 만든 것과 같은 효과)
- Train에서는 사용하지만, Evaluation에서는 사용하지 않는다.
Overfitting을 피하기 위한 방법들
- 더 많은 데이터를 사용한다.
- 특성의 개수를 줄인다.
- Regularization을 시행한다.
- 하지만 Dropout이 제일 낮다.
Batch Normalization
Gradient Vanishing
- gradient가 소멸되어서 생기는 문제다.
Gradient Exploding
- gradient가 너무 커져서 생기는 문제다.(coverage 되지 않는다)
위의 문제에 대한 해결방법
- Activation Function을 바꾼다.(ex. 시그모이드가 아닌 ReLU를 이용한다.)
- Weight Initialization을 잘한다.
- Learning Rate를 작게한다.
- Batch Normalization을 시행한다.
Internal Covariate Shift
- 레이어가 올라갈수록 학습 데이터 분포가 쏠린다.
- 공분산이 바뀌어서 같은 출력이 나와야 할 데이터 인풋 하나하나마다 다른 분석이 된다.
Batch Normalization
- 한 Batch 내에서 feature 각각에 대해 Normalization을 시행한다.

- 시그모이드 함수에 들어갈 x는 -1에서 1사이이다.
- 그대로 들어가면 y값은 그냥 선형함수 모양으로 나오는 y이다.
- 그래서 rx + b를 해서 시그모이드함수에서 넓게, 그리고 살짝 편향되게 한다.
- 평가할 때에는 평가 데이터의 sample mean, variance를 이용하는 것이 아니라, learnging mean, learning variance를 이용한다.
- batch마다 혹은 구성마다 output이 달라질 수 있는 것을 방지한다. (혹은 Train과 Test간의 데이터 구성 차이에 따른 결과 차이를 극복한다.)