Leacture: Deep Learning for everyone
Outline
- CNN
- RNN
- RNN hihello and charseq
- Cross Entropy Loss
합성곱 신경망: CNN(Convolutional Neural Network)
Convolution
-
이미지 위에서 stride 값 만큼 filter(kernel)을 이동 시키면서 겹치는 부분의 각 원소의 값을 곱해서 모두 더한 값을 출력으로 하는 연산이다.
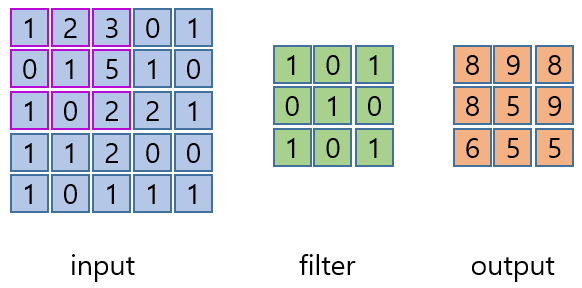
- 첫 번째 convolutoin 연산
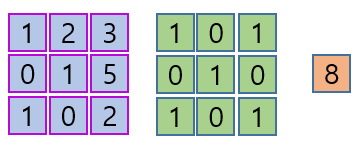
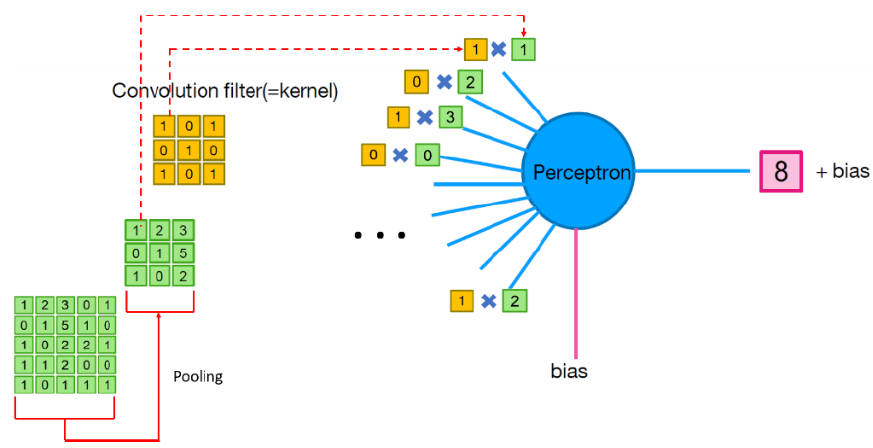
(1x1) + (2x0) + (3x1) +
(0x0) + (1x1) + (5x0) +
(1x1) + (0x0) + (2x1) = 8
- 첫 번째 convolutoin 연산
스트라이드(stride)
- filter를 한번에 얼마나 이동할 것인가를 나타낸다.
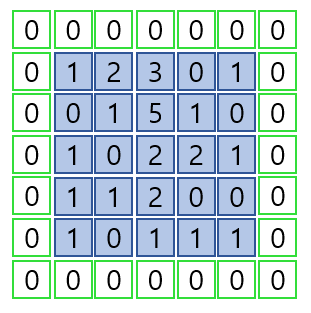
패딩(padding)
- zero-padding; 합성곱 연산을 수행하기 전에 입력 데이터 주변을 특정값으로 채운다.
[Convolution 연산]
- torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True))
입력의 형태
- input type: torch.Tensor
- input shape: (N x C x H x W) (batch_size, channel, height, width)
Output Size
- input size (N, Cin, H, W) : (batch_size, channel, height, width)
- output (N, Cout, Hout, Wout)
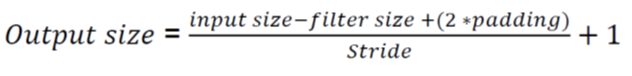
Pooling
- 일정 크기의 블록을 통합하여 하나의 대푯갑으로 대체하는 연산이다.
- 입력데이터의 차원 감소하여 신경망의 계산효율성이 좋아지고 메모리 요구량의 감소가 일어난다.
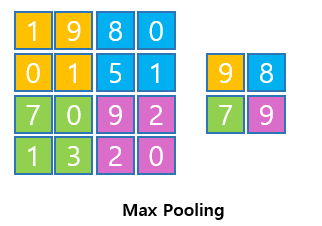
Max Pooling
- 지정된 블록 내의 원소 중에서 최대값을 대표값으로 선택한다.
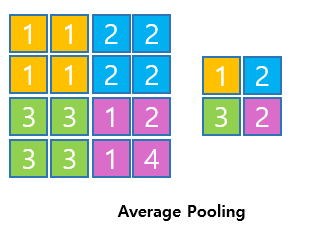
Average Pooling
- average pooling = 2일때 2x2사이즈 안에서 평균값을 출력한다.
[Pooling 연산]
- torch.nn.MaxPool2d(kernel_size, stride=None,padding=0, dilation=1, return_indices=False, ceil_mode=False)
Neuron 과 Convolution 의 관계
- Perceptron에서 Convolution이 일어나는 과정이다.
MNIST_CNN
딥러닝을 학습시키는 단계
- 라이브러리 가져오기
- GPU 사용설정
- 데이터셋을 가져오고 로더 만들기
- Parameter 결정
- 학습 모델 만들기
- Loss function & Optimizer
- Training
- Test model Performance
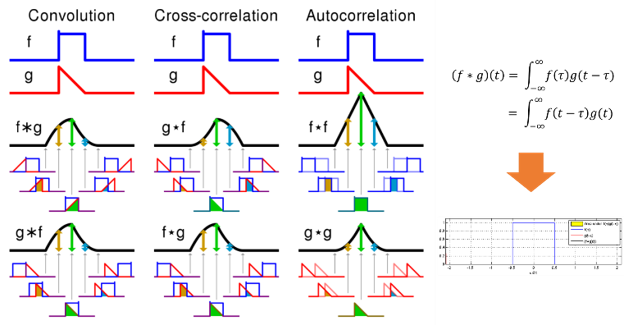
What is Convolution???
- 필터 g가 f를 지나가면서 둘이 얼마나 유사한지를 계산한다. (적분)
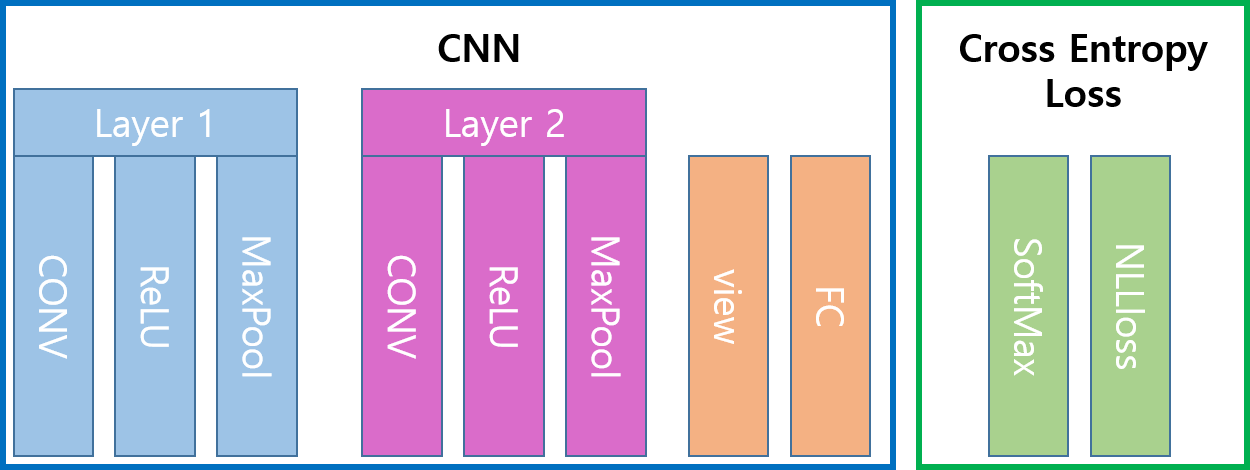
MNIST를 이용하여 만들 CNN 구조
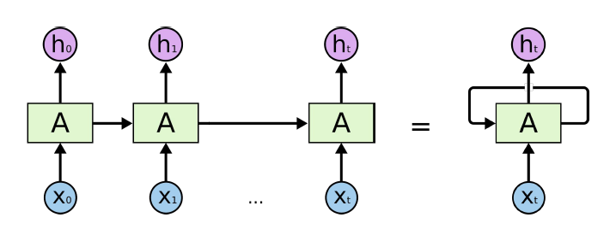
순환 신경망: RNN(Recurrent Neural Network)
- 반복적이고 순차적인 데이터(Sequential data)학습에 특화된 인공신경망의 한 종류이다.
-
내부의 순환구조가 들어있으며 이를 이용하여 과거의 학습을 현재 학습에 반영한다.
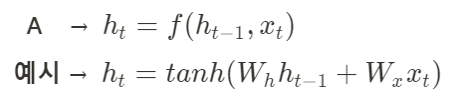
- ht-1: 이전 상태값
- xt: 현재 입력값
- fw: w(Weight) parameter를 가지고 계산하는 함수
- ht: 새로운 상태값
RNN의 다양한 구조
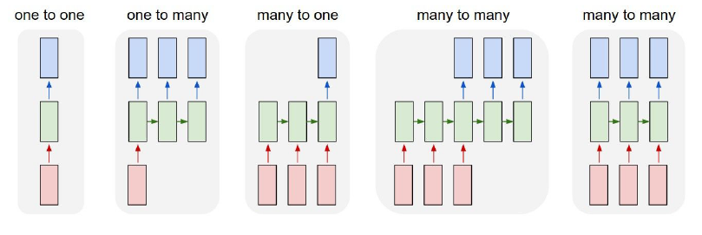
- RNN의 발전된 형태로 LSTM과 GRU가 있다.
RNN hihello and charseq
- One hot encoding을 이용하여 RNN에 넣어 줘야 할 데이터를 가공한 후 학습 시킨다.
- One-hot encoding: 벡터의 한 요소만 1로, 나머지 요소는 0으로 나타내는 표현 방식이다.
Hihello 데이터 준비 과정
import torch
import torch.nn as nn
char_set = ['h', 'i', 'e', 'l', 'o']
#hyper parameters
input_size = len(char_set)
hidden_size = len(char_set)
learning_rate = 0.1
#data setting
x_data = [[0, 1, 0, 2, 3, 3]]
x_one_hot = [[[1, 0, 0, 0, 0],
[0, 1, 0, 0, 0],
[1, 0, 0, 0, 0],
[0, 0, 1, 0, 0],
[0, 0, 0, 1, 0],
[0, 0, 0, 1, 0]]]
y_data = [[1, 0, 2, 3, 3, 4]]
X = torch.FloatTensor(x_one_hot)
Y = torch.LongTensor(y_data)
Charseq 데이터 준비과정
sample = "if you want you"
#make dictionary
char_set = list(set(sample))
#set으로 중복된 문자 제거 후 list로 만든다.
char_dic = {c: i for i, c in enumerate(char_set)}
# char : idx 형태의 딕셔너리를 만든다.
#hyper parameters
dic_size = len(char_dic)
hidden_size = len(char_dic)
learning_rate = 0.1
#data setting
sample_idx = [char_dic[c] for c in sample]
#char들을 idx로 바꾼 리스트를 만든다.
x_data = [sample_idx[:-1]] #맨 마지막 문자를 뺀 부분
#np.eye로 identity matrix를 만들어서 one-hot 벡터를 가져온다.
x_one_hot = [np.eye(dic_size)[x] for x in x_data]
y_data = [sample_idx[1:]] #맨 처음 문자를 뺀 부분
X = torch.FloatTensor(x_one_hot)
Y = torch.LongTensor(y_data)
Cross Entropy Loss
- 보통 Classification에서 많이 사용된다.
- 첫 번째 파라미터에 대해서는 모델의 아웃풋을 주어야 하고, 두번째 파라미터에서는 정답 레이블을 주어야 한다. 순서를 바꾸면 동작하지 않을 수 있다.
# loss & optimizer setting
criterion = torch.nn.CrossEntropyLoss()
...
loss = criterion(outputs.view(-1, input_size), Y.view(-1))