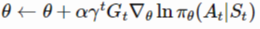Outline
- 기존 RNN을 개선한 LSTM, GRU 모델
- Attention with seq2seq
- Deep SARSA & Policy Gradient
LSTM(Long Short Term Memory), GRU(Gated Recurrent Unit)
RNN
- 기존 RNN은 이전 타임스텝의 정보 (hidden state)를 다음 타임스텝으로 전달하는 방식 하지만 시퀸스가 너무 길어질 경우 정보를 충분히 전달하지 못할 수 있다.
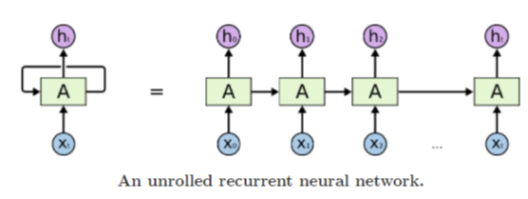

- 위 그림과 같이 넓은 간격에서 앞 쪽의 타임스텝의 정보가 충분히 전달되지 못하는 문제가 발생한다.
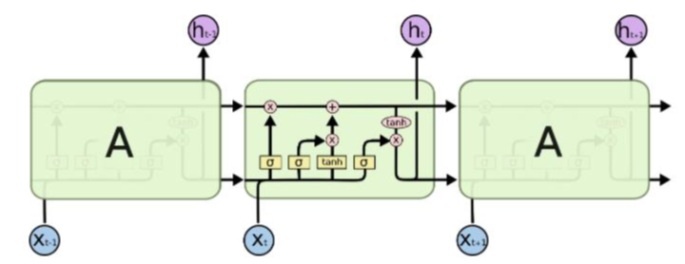
LSTM
- LSTM은 cell state라는 역할이 존재하며, Input gate, Output gate, Forget gate를 통해 계산이 이루어진다.
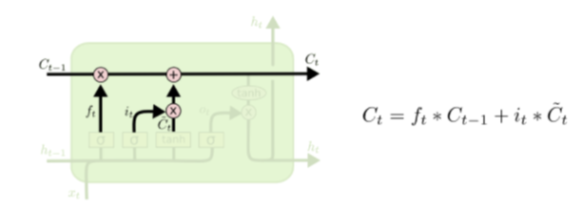
Cell State
- Gate들과 함께 정보를 선택적으로 활용하여 다음 시점으로 넘겨준다. 각 Gate의 결과를 더해 시퀸스가 길어도 오차를 제대로 전달할 수 있게 한다.
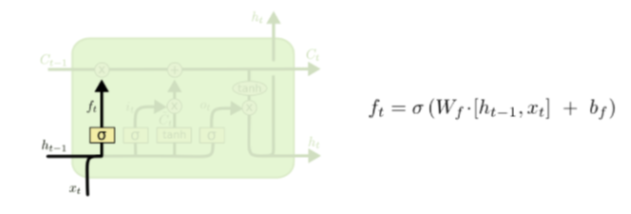
Forget Gate
- 과거의 정보를 기억할지 잊을지를 결정하는 단계이다. 𝑠𝑖𝑔𝑚𝑜𝑖𝑑함수를 이용하여 0에 가까울수록 정보를 잊고, 1에 가까울수록 정보를 기억한다.
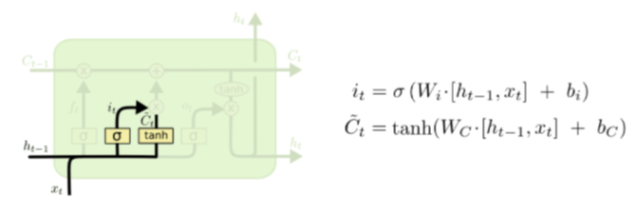
Input Gate
- 현재의 정보를 잊을지 기억할지 결정하는 gate이다. 전 시점의 hidden state와 현 시점의 입력을 통해 연산을 진행한다. 𝑡𝑎𝑛ℎ를 사용하여 현재 정보를 얼마나 더할지 결정한다.
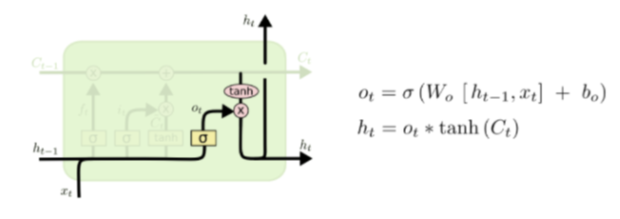
Output Gate
- 최종적인 출력값이다. 현 시점의 hidden state는 현 시점의 cell state와 계산되어 출력되며, 다음 시점으로 hidden state를 넘긴다.
GRU
- 기존의 LSTM구조를 간단하게 개선한 모델이다. LSTM과는 다르게 Reset gate, Update gate 2개의 gate만을 사용한다. 또한 cell state와 hidden state가 합쳐져 하나의 hidden state로 표현한다.
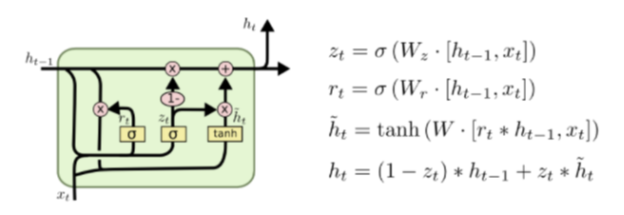
Reset Gate
- 두 번째 식에 해당하는 부분이다. 이전 시점의 hidden state와 현 시점의 x를 𝑠𝑖𝑔𝑚𝑜𝑖𝑑를 적용하여 구한다. 즉 이전 hidden state를 얼마나 활용할지 결정한다.
Update Gate
- 과거와 현재의 정보를 얼마나 반영할지 비율을 정하는 부분이다. 𝑧는 현재의 정보에 대한것, 1−𝑧는 과거 정보에 대한 반영 비율을 나타낸다.
seq2seq Attention
- seq2seq은 입력 시퀸스를 받아 출력 시퀸스를 생성하는 모델이다. 가변적인 입 출력 시퀸스 길이를 처리할 수 있다. 하지만 vanishing gradient와 정보의 손실 문제가 발생한다. (bottleneck problem)
- 특정한 정보를 전달하기 위해 Attention Mechanism 사용한다.
- 디코더의 매 시점마다 인코더의 전체 입력을 다시 한번 참조할 수 있게 도와주는 역할을 한다.
-
전체 입력을 동일하게 참조하는 것이 아닌 현재 예측해야 할 부분과 가장 연관있는 부분에 더 집중적으로 참조한다.
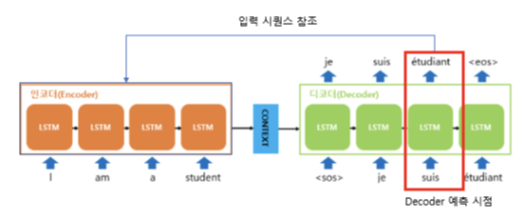
[입력 시퀸스 참조]
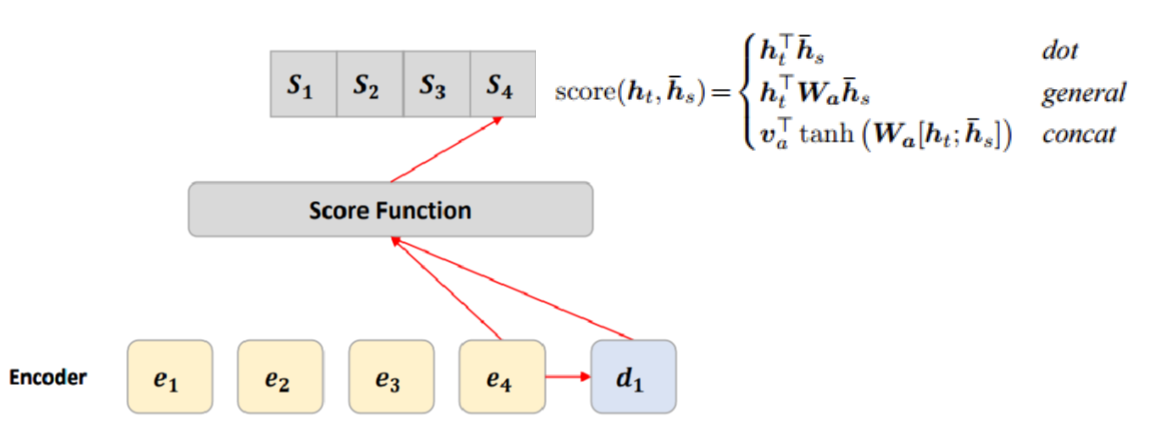
[Score Function]
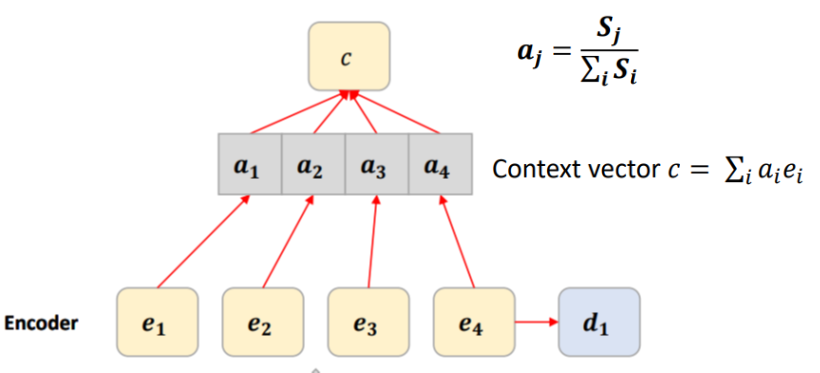
[Normalize (Score Softmax를 취한다.)]
[c와 d를 가지고 다음 언어 예측]
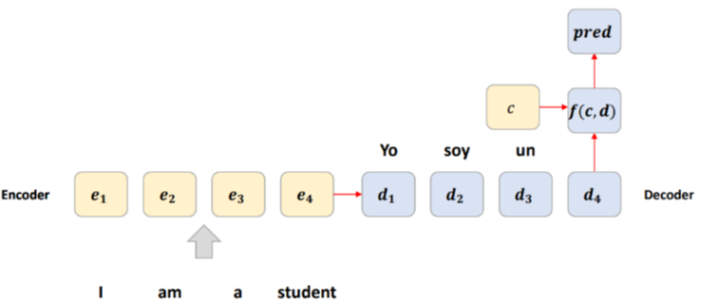
- c와 d를 가지고 다음 언어를 예측할 수 있다. 이 때, 단어 예측을 위한 f는 Neural Network를 사용한다.
Deep SARSA & Policy Gradient
Deep SARSA
- 그리드 월드에서의 문제에서 장애물의 개수가 늘어나고 움직이는 경우에 대한 방법이다.
- 살사 알고리즘에서 q function을 인공신경망으로 근사한다.
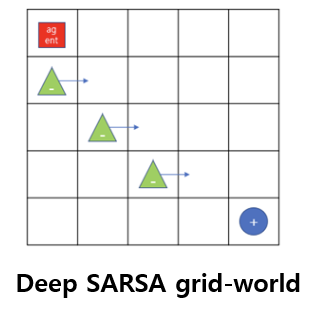
- 딥살사는 인공신경망을 사용하기에 기존 테이블 형태 강화학습처럼 하나의 큐함수를 업데이트하지 않고 경사하강법을 사용한다.
- 오차함수를 정의하여 인공신경망을 업데이트한다.
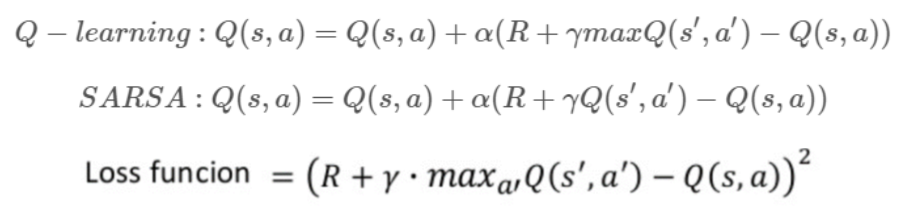
Policy Gradient
- 인공신경망으로 정책(policy)을 근사하여 정책신경망을 업데이트하는 것을 Policy Gradient 라고 한다.
- 반환값을 업데이트의 기준으로 사용하는 것은 REINFORCEMENT 알고리즘이라고 한다.
-
네트워크를 업데이트 하기 위한 오류함수 감가된 보상과 gradient식을 사용하여 REINFORCE업데이트 식을 구하면 다음과 같다.
오류함수
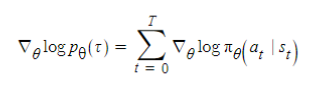
감가된 보상과 Gradient
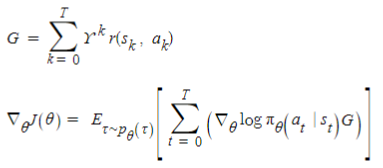
REINFORCE 업데이트 식