Outline
- DQN
- Cartpole
- Cartpole Code
DQN(Deep Q Network)
DQN이란?
- DQN 알고리즘은 2013년 딥마인드가 “Playing Atari with Deep Reinforcement Learning”이라는 논문에서 소개되었다.
- DQN은 Deep SARSA와는 다르게 Q learning의 Q Function을 업데이트 한다.
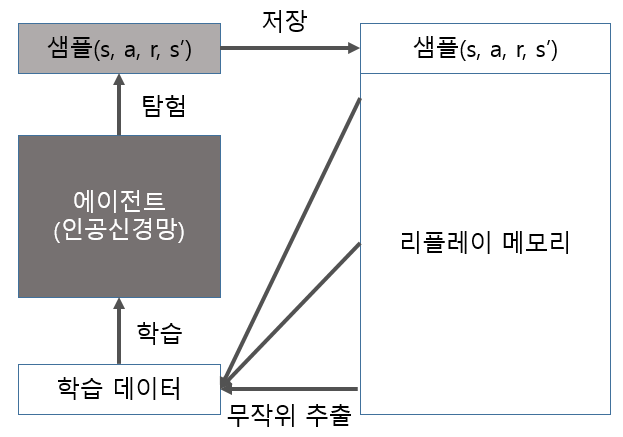
- Q Function 업데이트를 가능하게 하기 위해 경험 리플레이를 사용한다.
- 경험 리플레이는 에이전트가 환경에서 탐험하며 얻는 샘플(s, a, r, s’)을 메모리에 저장하는것이다.
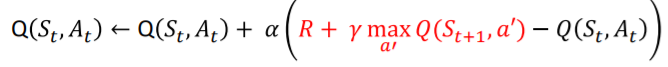
Q-learning의 Q함수 업데이트 식
DQN의 특징
- 타깃 신경망을 사용한다.
- 경험 리플레이를 사용 사용하는 에이전트는 매 타임스텝마다 리플레이 메모리에서 샘플을 배치로 추출해서 학습에 사용한다.
- 오류함수로 MSE사용한다.
경험 리플레이
- 환경에서 에이전트가 탐험하며 얻는 샘플(s,a,r,s’)를 메모리에 저장한다.
- 샘플을 저장하는 메모리는 리플레이 메모리이다.
- 에이전트가 학습할 때 샘플을 무작위로 뽑아 샘플에 대해 인공신경망을 업데이트 한다.
- 샘플간의 상관관계를 없앨 수 있다.
- 현재 에이전트가 경험하고 있는 상황이 아닌 다양한 과거의 상황으로부터 학습하기 때문에 오프폴리시가 적합하다.
- 그래서 q learning을 경험 리플레이 메모리와 사용하는것이다.
리플레이 메모리
- 크기가 정해져 있다.
- 메모리가 차면 처음들어온 것부터 삭제된다. (큐 방식)
- 에이전트가 학습해서 높은 점수를 받으면 더 좋은 샘플이 리플레이 메모리에 저장된다.
- 메모리에서 추출한 여러개의 샘플을 통해 인공신경망을 업데이트 하므로 학습이 안정적이다.
- 여러개의 gradient를 구하면 하나의 데이터에서 gradient를 구하는것보다 값 자체의 변화가 줄어 인공신경망 업데이트가 안정적이다.
[DQN Algorithm 구조]
Cartpole
Markov Decision Process (MDP)
-
상태(state) : 카트의 위치, 속도, 폴의 각도, 각속도
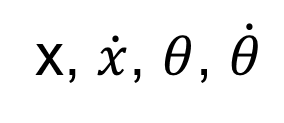
- 행동(action) : 왼쪽(0), 오른쪽(1)
-
보상(reward) : 카트폴이 쓰러지지 않고 버티는 시간
- 예를들어, 10초를 버티면 보상은 +10
- 여기선 단위가 초가 아니라 타임스텝
- 최대 500타임스텝까지 버틸 수 있음. 보상은 +500
- 중간에 카트폴이 쓰러지면 -100
- 감가율 : Q함수에 대한 discount
Cartpole Code
Environments
# CartPole-v1 환경, v1은 최대 타임스텝 500, v0는 최대 타임스텝 200
env = gym.make('CartPole-v1')
state_size = env.observation_space.shape[0] # 4
action_size = env.action_space.n # 2
print("state_size:", state_size)
print("action_size:", action_size)
- Cartpole을 실행할 환경을 생성한다.
- CartPole-v0 과 v1의 차이는 최대 타임스텝의 수 (각각 200, 500) - state_size = 4 (카트의 위치, 속도, 폴의 각도, 각속도)
- action_size = 2 (왼쪽으로 움직이기, 오른쪽으로 움직이기)
DQNAgent Class
class DQNAgent:
def __init__(self, state_size, action_size):
# 클래스를 사용할 떄 자동으로 실행된다.
def build_model(self):
# 상태가 입력된다. 큐함수가 출력인 인공신경망을 생성한다.
def update_target_model(self):
# 타겟 모델을 모델의 가중치로 업데이트
def get_action(self, state):
# 입실론 탐욕 정책으로 행동 선택
def append_sample(self, state, action, reward, next_state, done):
# 샘플 <s, a, r, s'>을 리플레이 메모리에 저장
# done : false 였다가 게임이 끝나면 True로 바뀜
def train_model(self):
# 리플레이 메모리에서 배치 사이즈 만큼 무작위로 추출해서 학습하는 함수
- DQNAgent class를 구성하고 있는 메서드들이다.
def __init__
def __init__(self, state_size, action_size):
self.render = False
self.load_model = False
# 상태와 행동의 크기 정의
self.state_size = state_size # 4
self.action_size = action_size # 2
# DQN hyperparameter
self.discount_factor = 0.99
self.learning_rate = 0.001
# epsilon이 1이면 무조건 무작위로 행동을 선택한다.
self.epsilon = 1.0
self.epsilon_decay = 0.999
# 지속적인 탐험을 위해 epsilon을 0으로 만들지 않고 하한선을 설정함.
self.epsilon_min = 0.01
self.batch_size = 64
self.train_start = 1000
# 리플레이 메모리, 최대크기 2000
self.memory = deque(maxlen = 2000)
# 모델과 타겟 모델 생성
# DQN의 특징 중 하나는 타겟신경망(모델)을 사용한다는 것
# 가중치가 무작위로 초기화 되기 때문에 현재 두 모델이 같지 않음
self.model = self.build_model()
self.target_model = self.build_model()
# 타겟 모델 초기화
self.update_target_model()
if self.load_model:
self.model.load_weights("./save_model/cartpole_dqn.h5")
I. Epsilon Greedy Algorithm
- epsilon decay : 1.0 에서 0.999씩 곱해지며 decay 된다.
- epsilon이 1이면 무조건 무작위로 행동을 선택한다.
- epsilon min : decay되는 최솟값이다.
II. Replay Memory
- Batch_size : 리플레이 메모리에서 무작위로 추출할 샘플의 사이즈다.
- Train_start : 리플레이 메모리에 1000개가 쌓이면 학습을 시작한다.
- Memory : 리플레이 메모리에 2000개가 쌓이면 일반적인 큐의 규칙에 의해 처음 들어온 데이터부터 삭제가 된다.
III. Target Network
- Model, target_model : 모델과 타깃모델 생성
- Q함수의 업데이트는 다음상태 예측값을 통해 현재 상태를 예측하는 부트스트랩 방식이다.
- 부트스트랩의 문제점은 업데이트 목표가 계속 바뀐다.
- 이를 방지하기 위해 정답을 만들어 내는 신경망을 한 에피소드동안 유지한다.
- 타겟 신경망을 따로 만들어서 정답에 해당하는 값을 구한다.
- 구한 정답을 통해 다른 인공신경망을 계속 학습시키며 타겟 신경망은 한 에피소드 마다 학습된 인공신경망으로 업데이트 한다.
build_model
def build_model(self):
model = Sequential()
model.add(Dense(24, input_dim = self.state_size, activation = 'relu', kernel_initializer = 'he_uniform'))
model.add(Dense(24, activation = 'relu', kernel_initializer = 'he_uniform'))
model.add(Dense(self.action_size, activation = 'linear', kernel_initializer = 'he_uniform'))
model.summary()
model.compile(loss = 'mse', optimizer = Adam(lr = self.learning_rate))
return model
update_target_model
def update_target_model(self):
self.target_model.set_weights(self.model.get_weights())
get_action
def get_action(self, state):
# 2 <= 3 : 첫번째 숫자가 두번째 보다 같거나 더 작은가? -> True of False
# np.random.rand() : 0~1 사이 실수 1개 / np.random.rand(5) : 0~1 사이 실수 5개
# random.randrange(5) : 0~4 임의의 정수 / random.randrange(-5,5) : -5 ~ 4 임의의 정수
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
else:
# q_value = [[-1.3104991 -1.6175464]]
# q_value[0] = [-1.3104991 -1.6175464]
# np.argmax(q_value[0]) = -1.3104991
q_value = self.model.predict(state)
return np.argmax(q_value[0])
- np.random.rand() : 0~1 사이 임의의 실수 1개
- self.epsilon : Epsilon Greedy Algorithm의 epsilon 값
- epsilon값이 더 크면 무작위 행동(왼쪽 or 오른쪽으로 움직이기)
- 그게 아니라면 계산한 두개의 Q값들 중 더 큰 값을 반환한다.
append_ sample
def append_sample(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
triain_model
def train_model(self):
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
# 메모리에서 배치 크기만큼 무작위로 샘플 추출
# mini_batch의 모양: 64 x 5
# np.shape(mini_batch)
mini_batch = random.sample(self.memory, self.batch_size)
# 모델의 업데이트는 배치로 샘플들을 모아서 한 번에 진행하기 때문에
# model.fit(states, target)에 들어가는 states는 배치여야함
# 따라서 np.zeros를 사용해 states의 형태를 배치 형태로 지정함.
# np.zeros( (2, 3) ) : 2x3 영행렬
states = np.zeros((self.batch_size, self.state_size)) # 64 x 4
next_states = np.zeros((self.batch_size, self.state_size)) # 64 x 4
actions, rewards, dones = [], [], []
# def append_sample(self, state, action, reward, next_state, done):
# mini_batch의 모양: 64 x 5
# actions의 모양 : np.shape(actions)
for i in range(self.batch_size):
states[i] = mini_batch[i][0]
actions.append(mini_batch[i][1])
rewards.append(mini_batch[i][2])
next_states[i] = mini_batch[i][3]
dones.append(mini_batch[i][4])
# self.model = self.build_model()
# self.target_model = self.build_model()
# target 의 size: 64 x 2
# target_val 의 size : 64 x 2
target = self.model.predict(states) # 큐함수 값
target_val = self.target_model.predict(next_states) # 정답 큐함수 값 (부트스트랩)
# 벨만 최적 방정식을 이용한 업데이트 타겟
# amax 함수는 array 의 최댓값을 반환하는 함수
for i in range(self.batch_size): # i: 0 ~ 63
# actions[i] : 0 or 1
# dones[i] : False or True
if dones[i]:
target[i][actions[i]] = rewards[i]
else:
target[i][actions[i]] = rewards[i] + self.discount_factor * (np.amax(target_val[i]))
- target은 현재 상태에 대한 모델의 큐함수이다.
- target_val은 다음 상태에 대한 타겟 모델의 큐함수이다.
Train
scores, episodes = [], []
N_EPISODES = 100
for e in range(N_EPISODES):
done = False
score = 0
# env 초기화
# state의 모양 : 4
state = env.reset()
# state의 모양 : 4 -> 1 x 4
state = np.reshape(state, [1, state_size])
# done : false 였다가 한 에피소드가 끝나면 True로 바뀜
while not done:
# render = True 이면 학습영상 보여줌
if agent.render:
env.render()
# 현재 상태로 행동을 선택
action = agent.get_action(state) # q함수를 얻었다.
# 선택한 행동으로 환경에서 한 타임스텝 진행
# next_state = np.reshape(next_state, [1, state_size]) : 1x1 -> 1x4
# info : {} / 넣고싶은 정보가 있으면 추가하면 됨. 없으면 안넣어도 됨.
next_state, reward, done, info = env.step(action)
next_state = np.reshape(next_state, [1, state_size])
# 에피소드가 중간에 끝나면 -100 보상
# reward = reward if not done else -100
reward = reward if not done or score == 499 else -100
# 리플레이 메모리에 샘플 <s,a,r,s'> 저장
agent.append_sample(state, action, reward, next_state, done)
# 매 타임스텝마다 학습문
# self.train_start = 1000
# 이렇게 하는 이유는 DQN에서는 배치로 학습하기 때문에 샘플이 어느정도 모일때 까지 기다려야 하기때문.
if len(agent.memory) >= agent.train_start:
agent.train_model()
score += reward
state = next_state
if done:
# 각 에피소드마다 타겟 모델을 모델의 가중치로 업데이트
agent.update_target_model()
score = score if score == 500 else score + 100
# 에피소드 마다 학습결과 출력
scores.append(score)
episodes.append(e)
pylab.plot(episodes, scores, 'b')
if not os.path.exists("./save_graph"):
os.makedirs("./save_graph")
pylab.savefig("./save_graph/cartpole_dqn.png")
print("episode:", e, " score:", score, " memory length:", len(agent.memory), " epsilon:", agent.epsilon)
# 이전 10개 에피소드의 점수 평균이 490보다 크면 학습 중단
# np.mean([1, 2, 3]) = 2.0 / np.mean() : 평균
# min([1, 2, 3]) = 1 / min : 가장 작은 값
# a = [ 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20]
# print(a[-10:])
# b = [1,2,3,4,5,6,7,8,9]
# print(b[-9:])
if np.mean(scores[-min(10, len(scores)):]) > 490:
if not os.path.exists("./save_model"):
os.makedirs("./save_model")
agent.model.save_weights("./save_model/cartpole_dqn.h5")
sys.exit()